

By David Kudler
Once you’ve converted your ebook, the first impulse you’ll have is to upload the file and hit Publish.
Finished! Whoohoo!
Not so fast.
Before they allow you to sell your beautiful new ebook on their site, most retailers require some form of validation. They need to be sure that the file will meet the standards in order to display properly on their ereader.
ePubcheck
Most often, the tool they use is some variation on epubcheck, the Java app developed by the creators of the ePub standard for just this purpose.
It is, then, a really good idea to run your ebook through epubcheck before uploading it so that you can be (fairly) sure that your ebook will pass inspection. There are a few ways to do that:
- Download the latest version of epubcheck and run it on your computer
- Use a plugin that runs epubcheck
- Upload to the IDPF validator
Download epubcheck
So the most straightforward way to validate your ebook is to download the actual Java app and run it on your computer — Windows, macOS, Linux, whatever.
The app is available on GitHub. Click on the title of the latest release (at the top of the page). [1] Then go down to the bottom of the release page and click on the link that looks like this: epubcheck-[VERSION-NUMBER].zip
Download it, un-ZIP the archive, [2] and then fire up your command line.
If I just lost you, don’t worry — you can skip to the next section.
In the command line, invoke epubcheck using the following syntax: java -jar /path/to/your/version/of/epubcheck-4.0.2/epubcheck.jar /path/to/ebook/title.epub
Run a script
Alternately, you can run a script inside of your ebook-editing software. I have a plug-in that I use within Sigil.
Running it’s a lot easier than running epubcheck in the command line. Within Sigil, with the file I want to check open and in the front window, I simply go to the Plugins menu and select Validation>ePubCheck.[3]
As with downloading the Java app directly, you’ll need to make sure that the version of the plugin is up to date.
Upload to the Validator
Alternatively, you can just upload the ebook file to the IDPF validator, which will run the latest version of epubcheck on your file.
The advantage to this method is that you’ll always be running the latest version of the script. You don’t have to download the Java app every few months. You don’t have to navigate the horrors of the command line. [4]
You just go to the validator.idpf.org web page, use the Choose File button to find and select your ebook file, and click on the Validate button. Done.
The disadvantages of this method are:
- The file size is (as marked on the page) limited to 10MB. Unless your ebook is heavily illustrated (and you haven’t followed my image prep guidelines) or contains audio or video, that probably isn’t a problem.
- If you’re on public wifi, your file might theoretically be vulnerable to being snatched. Unlikely, however, since what they were really looking for was your Social Security number, your passwords, and the cute video of your cat playing the kazoo.
Which is to say, 99 times out of 100, I use the website.
Exterminate! Exterminate! (Dealing with Errors)
Once you’ve run epubcheck — however you’ve run it — you might get a clean bill of health, in which case, hurray! Go down to the end of this chapter to see what to do next.
More likely, you’ll get a list listing anywhere from a few to thousands of errors and warnings.
Let’s track down those bugs, shall we?
Whatever method you use to run epubcheck, you’ll get a table that looks something like this:
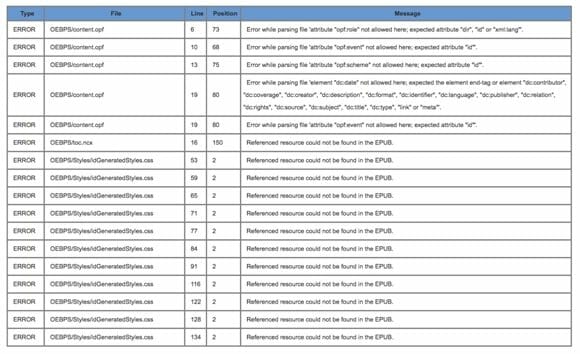
(That’s the results of a check on a file exported by InDesign, by the way. I’ve had files created in nearly all of the other conversion tools fail validation out of the gate. This is one reason to learn to edit your own ePub files!)
The first column is the critical one: if the field reads WARNING rather than ERROR, you can fix it if you’d like, but it won’t keep your file from passing validation. It may mean that your ebook won’t look the way you want it to, but hey, first things first, right?
ERROR on the other hand means failure — you won’t be able to upload your ebook to any of the retailer sites until you take care of the problem.
You may be able to fix the error in your original file, but most likely the problem was created on conversion, so you’ll need to edit the ePub file.
Column #2 tells you which file inside of your ebook the error originates from. [5] So, for example, in the table above, the first few errors occur within the OPF file, contents.opf.
Column #3 tells you what line number the error occurs at. If you have the file open in Sigil (or Calibre or Dreamweaver or whatever), you should be able to use the numbers on the left side of the screen to find the problematic line.
Column #4 tells you what character number the error occurs at. This is a bit more problematic. If the line’s short, you should be able to count from the beginning of the line to find the problem. If, however, the line contains a full paragraph with hundreds or even thousands of characters, you may find yourself pulling your hair out.
This is where it’s good to remember that line breaks in HTML files have no meaning, as far as the way your ebook displays.
So if epubcheck tells you that the error occurs in character 897 of an 1152-character line, just hit return somewhere in the middle to add a line break. (NB — DON’T add a break inside of a tag. That will mess things up. But between tags? No problem.)
Run epubcheck again and see if you have a clearer idea of where on the line the problem occurs.
Repeat until you can nail the problem down.
I once had to break a 250-word paragraph down to nearly 250 lines before I identified the problem. Fun, right?
Stomping Bugs
Once you’ve figured out where the problem is, you need to look at the actual error — the “message” in column #5.
Unfortunately, a lot of those errors are opaque at best.
Let’s look at the ones in the list above:
Error while parsing file ‘attribute “opf:role” not allowed here
Looking at the matching line (#6) in the file content.opf (the Package file), I see the following:
<dc:creator xmlns:opf=”https://www.idpf.org/2007/opf” opf:role=”aut”>David Kudler</dc:creator>
So the attribute opf:role is perfectly legitimate — for ePub3 files. Unfortunately, if I look up at line 2 of that ebook’s OPF file, I can see that the ePub version for this ebook is version=”2.0″. Oops.
I can simply delete opf:role=”aut”. I can also use Sigil’s metadata editor (Tools>Metadata Editor…) to add the correct syntax to the metadata section of the file. This way, ereaders will list the proper author name in their library displays.
The next two errors as well as the fifth (for opf:event and opf:scheme) can be dealt with the same way.
Error while parsing file ‘element “dc:date” not allowed here
Somehow, the file managed to have two separate lines:
<dc:date id=”dat”>2016-06-15</dc:date>
And
<dc:date id=”dat”>2015-11-19</dc:date>
Note that the id attributes for those two lines are identical — id=”dat”. Nope. Can’t have that. Each id needs to be unique. Since there was already an id=”dat”, the second line spit out the error.
To fix this, either delete the second line, or change the id attribute (and any other references to that attribute).
Since first line referred to the release date of the book and the second line referred to the creation date of the file, I changed the id of the second line to read id=”creation-date”.
Referenced resource could not be found in the EPUB.
This is an error that pops up a lot. Basically, it means what it says: you can’t get there from here. The hyperlink points to a non-existent file or location.
The first time this error pops up in the epubcheck list above is a reference in the navigation document (OEBPS/tox.ncx) that looks like this:
<content src=”Text/Risuko_Complete_Draft_24.xhtml#_idParaDest-1″/>
As it happens, the id that the hyperlink is pointing to (#_idParaDest-1 in the file Risuko_Complete_Draft_24.xhtml) doesn’t exist. The file exists, but there’s no anchor with that id.
As it also happens, that link is supposed to point at the very top of the file. (This is most often the case with fiction, where the only navigation links are to the beginning of a chapter.) So I simply deleted the anchor (#_idParaDest-1) and left the filename (Risuko_Complete_Draft_24.xhtml). When next I ran epubcheck, the problem was gone.
However, if you’ve got subsections that your navigation file is pointing to, go into the HTML file in question and look for the section that this link is supposed to be pointing at.
Make sure that it is actually in the right file — sometimes, as you re-split the text, the anchor (the tag with the id attribute) moves to a new file, but the editing software doesn’t keep track of it. (Or you don’t, if you’re just using Dreamweaver or some other editing software.)
Make sure that the spelling and capitalization are correct — remember that Text is not the same as text. Ereaders are wonderful, but lacking in imagination, so you have to make every piece of code precisely correct. Sorry.
Another possible reason this can pop up is because you’ve included a web address without including the protocol. Basically, if you’re linking to an external web page, you need to include https:// (or https:// ) before the address. Likewise, if you’re linking to an email address, you need to include mailto: before the address. If you fail to do that, the ereader will look for the address inside the internal file structure of the ebook. If that’s not what you want, just add the protocol on before the address, and all will be well.
Let’s look at some other common errors that didn’t show up on that particular epubcheck run.
element “[HTML tag]” not allowed here; expected the element end-tag or element “address”, “blockquote”, “del”, “div”, “dl”, “h1”, “h2”, “h3”, “h4”, “h5”, “h6”, “hr”, “ins”, “noscript”, “ns:svg”, “ol”, “p”, “pre”, “script”, “table” or “ul”
This is a very common error that shows up in one of three circumstances:
- You’ve tried to place a block tag improperly inside another block tag
- You’ve tried to place an inline tag directly inside of the <body></body> tag
- You’ve failed to close one tag before opening another
A block tag improperly inside another block tag
As I’ve said, HTML tags can be placed one inside of another like Russian dolls. However, there are certain tags that can’t be stacked that way. You can’t place a paragraph tag (<p></p>) inside another paragraph. You can’t place an <h1></h1> tag inside an <h3></h3> (or vice-versa), etc.
If you really do need to use those tags, pull the inner tag out and place it after the outer tag. Otherwise, try substituting a <span></span> or other inline tag.
An inline tag directly inside of the <body></body> tag
Conversely, if you place an inline tag (i.e., <img/> or <br/>) or untagged text on the outermost level of the page (directly inside the <body></body> tag, the ereader won’t know what to do with it.
Simply surround the offending inline tag or text by a block tag like <p></p> or <caption></caption> or whatever, and all will be well.
Failed to close one tag before opening another
Remember, when you embed one tag inside of another, you have to close the innermost tag before closing the outermost.
Say I applied italics to a piece of text that spanned two paragraphs.
The following would generate an error (I’ve marked the opening and closing tags in red): [6]
<p>It is a truth universally acknowledged that a single man of good fortune <i>must be in want of a wife.</p>
<p>However little known the feelings or views of such a man may be on his first entering a neighborhood,</i> this truth is so well fixed in the minds of the surrounding families, that he is considered to be the rightful property of some one or other of their daughters.</p>
Note that the first paragraph closes before the italics do. As I said, ereaders are lacking in imagination — they need tags to come in the right order.
To make that work, you have to code it as follows (this time I marked the tags in green):
<p>It is a truth universally acknowledged that a single man of good fortune <i>must be in want of a wife. </i> </p>
<p><i>However little known the feelings or views of such a man may be on his first entering a neighborhood,</i> this truth is so well fixed in the minds of the surrounding families, that he is considered to be the rightful property of some one or other of their daughters.</p>
So now the italics tag is closed before the first paragraph close tag; then a new pair of tags set of the italics in the second paragraph — completely within the second set of paragraph tags.
Unmanifested file found/Referenced resource missing
These errors are mirror images of each other.
The first means that there’s a file in your ebook that isn’t included in the manifest section of the OPF file.
Make sure that there isn’t a spelling error in the manifest; if the file truly isn’t referenced, you can create a new reference that looks something like this: [7]
<item id=”filename” href=”Text/filename.xhtml” media-type=”application/xhtml+xml”/>
Alternatively, if you’re using a dedicated ebook editing package like Sigil or Calibre, simply rename the file. The software should recognize the new file and add it to the manifest.
The second error is the opposite — you’ve got a reference to a file (in your manifest or in a reference in one of the HTML files) that doesn’t exist in the ebook’s file structure. Perhaps there’s a reference to an image or chapter that inadvertently got deleted. Or perhaps, as I pointed out above, you’re actually referring to an external web resource but forgot to include the protocol (i.e., https:// or mailto: ).
When in doubt, Google
There are many, many more errors and warnings that epubcheck validation may turn up — far more than an article such as this could explore. Many of them are exceedingly obscure.
When in doubt, try using your web search engine of choice. Copy the error message (i.e., Element not allowed), and paste it into the search window with the word epubcheck. You’ll most likely get back dozens if not hundreds of hits — some of which will hopefully address your issue.
And, of course, once you’ve addressed all of the errors, save your file and run it through epubcheck again.
New/unresolved errors?
Rinse.
Repeat.
[1] Currently, the latest release is 4.0.2.
[2]By double-clicking on it, usually.
[3] You may need to download the latest version of Java to make this happen. Unless you’re a real fan of the early 2000s, for the love of Wozniak, don’t let the installer change your homepage to Yahoo. Just don’t.
[4] Okay. The command line isn’t so bad. The command line is your friend. However, you may not feel comfortable when confronted by the fact that your fancy twenty-first century computer with its fancy graphic interface is running on top of software that was originally created during the Nixon (or, in the case of Windows, Reagan) administration. Understood.
[5] More or less. Occasionally — particularly with navigation errors — this is just epubcheck’s indication that something’s wrong. Somewhere. You may have to do some sleuthing.
[6] Why you’d italicize the text like that I have no idea. Humor me.
[7] Actually, exactly like that — except with your missing filename and extension replacing the ones here. If the file isn’t an HTML file — if it’s an image or a sound file or a font or whatever, you’ll have to see what the appropriate file type (aka mimetype) would be. Check out the IDPF’s page on “core media types.”
Photo: Bigstockphoto
